AWS PythonのLambda関数でS3のファイル読み書き
PythonのLambda関数で「/tmp」に保存しているファイルは毎日削除されてしまうことを知り、S3に退避させる必要があったのでやってみた。
とりあえずS3にテスト用のバケットを作成して適当なjsonファイルをアップロードしておく
Lambdaでテスト用の関数を作成する
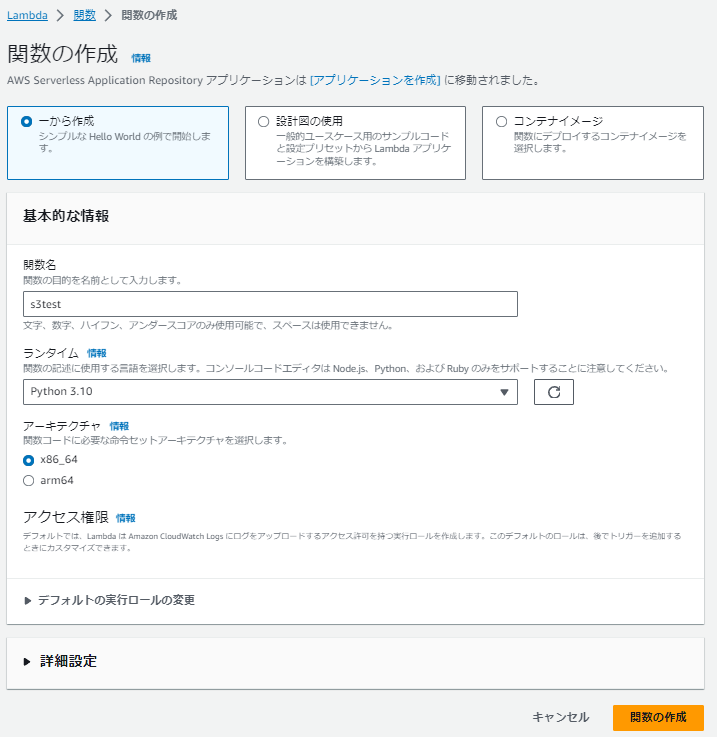
まずはアップロードしてあるファイルを取得するためのコードを書く
AWSをPythonから操作するためのライブラリとしてboto3を利用する
import boto3
boto3.resourceは無くなるわけではないが開発を止めるみたいな記事があったので
boto3.clientを使います。
お作法がちょっと違うだけでできることは同じだと思う。
boto3.clientを使ったjsonファイルの取得
s3 = boto3.client("s3")response = s3.get_object(Bucket = "testdata", Key = "test.json")body = response["Body"].read()
Bucketにバケット名
Keyにファイル名
responseのBodyにファイルの内容が入っているのでそれを取得します
ファイルのまま取得するのであれば
s3.download_file(Bucket = "testdata", Key = "test.json", Filename = "/tmp/test.json")
これだけですね。
今回のテストデータが50MBくらいあったのですが
取得に3秒くらいかかってる・・・
思ったより遅い
test.json→test.zipにしてみて取得後解凍するようにしてみたけど
解凍に時間かかってトータルそこまで変わらなかった・・・
boto3.resourceを使ったファイルの取得
s3 = boto3.resource("s3")obj = s3.Object("testdata","test.json")response = obj.get()body = response["Body"].read()
感覚的にresourceのほうがわかりやすいけど、開発が止まるならしょうがない
コードに書いて


テストしたらファイル取得できました。
S3にアクセスできないってエラーが出てる場合はポリシーの設定不備
Lambda関数の設定>アクセス権限
に表示されているロール名を許可されたものに変更するか
クリックしてロールの画面へいって
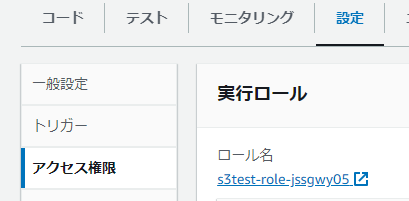
ポリシーのアタッチから

権限与えすぎですがテストなんで

コメント
コメントを投稿